

Содержание
Предисловие
Поставился я задачей собрать базу организаций и их данных, и соответственно сразу пришло в голову взять их из Яндекс Карт, так как, наверное, это самый большой и актуальный справочник в России, но это не точно)). В ручном режиме, всё это, собирать долго, да и лень, вот я и решил имея уже небольшую практику в парсинге данных, написать бота на Python, так как он в этом деле достаточно хорош и имеет готовые библиотеки и инструменты для этого.
Изначально я собирался парсить только email адреса, чтобы делать email рассылку, но как оказалось они больше в карточках организаций не отображаются. Поэтому я подумал и решил, что буду собирать все данные до которых можно будет, так сказать достучаться, например телефон, сайт, соц. сети и прочее, ведь в них тоже можно делать рассылки, либо ещё как то использовать. Но вопрос с парсингом email меня не оставлял в покое, поэтому я подумал и решил, так как мы будем ещё собирать и сайты организаций, то почему бы по ним тоже не пробежаться ботом и из них уже вытаскивать email адреса, ведь они почти присутствуют на каждом сайте.
Исходя из этого ставим следующие задачи:
Задачи
- – ???(пока нет) Сбор всех категорий (по городу)
- Сбор всех ссылок страниц из необходимой нам категории (или из всех категорий)
- Обход всех этих страниц и сбор такой информации как:
- Название организации
- Адрес
- Сайт
- Телефон
- Telegram
- Вконтакте
- Обход всех сайтов и сбор email адресов
Библиотеки и инструменты, которые нужно установить
1. Selenium
Установка:
pip install selenium
Источник и документации: https://pypi.org/project/selenium/
2. Chromedriver
Инструкция по установке
3. Beautiful Soup 4
Установка:
pip install bs4
Учтите, что мы будем использовать именно 4 версию.
Источник и документации: https://pypi.org/project/beautifulsoup4/
1 этап – сбор всех ссылок на страницы организаций
1
2
3
Сбор списка всех категорий и подкатегорий
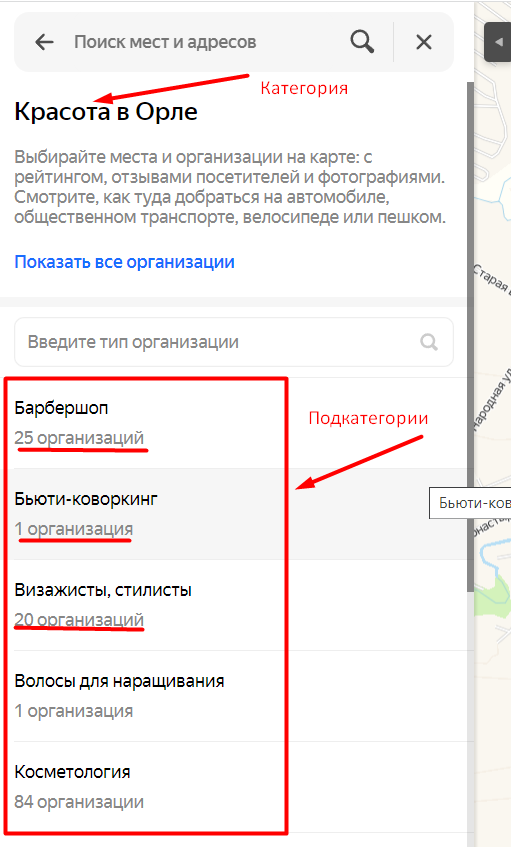
Вот так выглядит список всех категорий:

Данный блок, будем рассматривать на примере города – Орёл, но тоже самое можно будет применять и к другим городам, меняя некоторые данные в ссылке, давайте их и проанализируем.
Вот как выглядит url в браузере:
https://yandex.ru/maps/10/orel/catalog/?ll=36.131670%2C52.966168&z=11.9
Разберём ссылку
https://yandex.ru/maps/{id города}/{название города}/catalog/{координаты на карте}То есть, при выборе другого города на карте, у нас поменяются данные в фигурных скобках, а значение – {координаты на карте} можно изменять, увеличивая или уменьшая радиус поиска.
Вот так, например будет выглядеть ссылка для города – Брянск:
https://yandex.ru/maps/191/bryansk/catalog/?ll=34.377915%2C53.279273&z=11
Список ссылок категорий
Категории по всем городам имеют одинаковые id, их не так много, давайте перечислим их:
- Eда (1 ) : https://yandex.ru/maps/10/orel/catalog/1/?ll=36.069100%2C52.955841&z=13
- Продукты ( 7 ) : https://yandex.ru/maps/10/orel/catalog/7/?ll=36.069100%2C52.955841&z=13
- Медицина ( 6 ) : https://yandex.ru/maps/10/orel/catalog/6/?ll=36.069100%2C52.955841&z=13
- Магазины ( 8 ) : https://yandex.ru/maps/10/orel/catalog/8/?ll=36.069100%2C52.955841&z=13
- Авто ( 2 ) : https://yandex.ru/maps/10/orel/catalog/2/?ll=36.069100%2C52.955841&z=13
- Красота ( 5 ) : https://yandex.ru/maps/10/orel/catalog/5/?ll=36.069100%2C52.955841&z=13
- Стройка и ремонт ( 9 ) : https://yandex.ru/maps/10/orel/catalog/9/?ll=36.069100%2C52.955841&z=13
- Государство ( 10 ) : https://yandex.ru/maps/10/orel/catalog/10/?ll=36.069100%2C52.955841&z=13
- Почта ( 11 ) : https://yandex.ru/maps/10/orel/catalog/11/?ll=36.069100%2C52.955841&z=13
- Банки и финансы ( 12 ) : https://yandex.ru/maps/10/orel/catalog/12/?ll=36.069100%2C52.955841&z=13
- Услуги ( 13 ) : https://yandex.ru/maps/10/orel/catalog/13/?ll=36.069100%2C52.955841&z=13
- Транспорт ( 14 ) : https://yandex.ru/maps/10/orel/catalog/14/?ll=36.069100%2C52.955841&z=13
- Развлечения и отдых ( 3 ) : https://yandex.ru/maps/10/orel/catalog/3/?ll=36.069100%2C52.955841&z=13
- Туризм ( 4 ) : https://yandex.ru/maps/10/orel/catalog/4/?ll=36.069100%2C52.955841&z=13
- Образование ( 15 ) : https://yandex.ru/maps/10/orel/catalog/15/?ll=36.069100%2C52.955841&z=13
- Спорт ( 16 ) : https://yandex.ru/maps/10/orel/catalog/16/?ll=36.069100%2C52.955841&z=13
- Домашние животные ( 17 ) : https://yandex.ru/maps/10/orel/catalog/17/?ll=36.069100%2C52.955841&z=13
- Прочее ( 18 ) : https://yandex.ru/maps/10/orel/catalog/18/?ll=36.069100%2C52.955841&z=13
То есть, чтобы изменить ссылку для другого города, нужно поменять данные, которые я указал в кавычках, например категория Авто:
https://yandex.ru/maps/{id города}/{название города}/catalog/2/{координаты на карте}С категориями разобрались, теперь перейдём к подкатегориям этих категорий, ведь они то нам и нужны!
Парсинг подкатегорий
В основных категориях находятся подкатегории их мы и будем парсить в данном разделе, а в подкатегориях уже находятся списки организаций, что мы будем парсить в дальнейшем.
Сбор ссылок страниц организаций
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# Инициализация веб-драйвера (путь к chromedriver.exe)
driver = webdriver.Chrome()
# URL страницы с организациями
url = "https://yandex.ru/maps/10/orel/category/barber_shop/239628851835/?ll=36.051780%2C52.959312&sctx=ZAAAAAgBEAAaKAoSCX3qWKX0BkJAEc41zNB4ekpAEhIJ4IJsWb4u0T8RZvol4q3zrz8iBgABAgMEBSgKOABA7IQGSAFiEmxldG9fdl9nb3JvZGU9dHJ1ZWoCcnWdAc3MTD2gAQCoAQC9AaRXFSfCAZIBo6Kktd0F%2BfCxi%2BsEwL7E1hiYi%2F%2BJzAXljfL4ygG384HFzwLaxbyp9QO3sYLKgwHh%2B5CduAHEteOjpwO%2F2JKFBsbVmtU92Pu86o0B2oq94JcG5LKsw%2BcFnr7mm7oE%2FpudwMoEs%2BryiaUEsp%2Fu%2BKoBp%2FSpslzM5KXLmgOKnpDVkgXltpmgwgWt9sj%2BsQbW88CQiQLqAQDyAQD4AQCCAhpjYXRlZ29yeV9pZDooMjM5NjI4ODUxODM1KYoCDDIzOTYyODg1MTgzNZICAJoCDGRlc2t0b3AtbWFwc6oCCzk1NTczMjc1Nzgy&sll=36.051780%2C52.959312&sspn=0.890618%2C0.207006&z=11.27"
driver.get(url)
# Ждем некоторое время для загрузки начальных карточек
time.sleep(5)
# Получаем элемент <div> с классом "scroll__container"
scrollable_element = driver.find_element(By.CLASS_NAME, "scroll__container")
# Высота скролла (500px)
scroll_height = 500
# Начинаем скроллить
scroll_number = 1
while True:
# Выводим сообщение о начале скролла
print(f"Скролю {scroll_number}")
# Получаем текущее положение скролла
current_scroll_position = driver.execute_script("return arguments[0].scrollTop", scrollable_element)
# Скроллим на высоту scroll_height
driver.execute_script("arguments[0].scrollTop += arguments[1]", scrollable_element, scroll_height)
time.sleep(3) # Дайте странице время загрузиться
# Если текущая позиция скролла не изменилась, значит достигли конца
if current_scroll_position == driver.execute_script("return arguments[0].scrollTop", scrollable_element):
print("Скрол закончен")
break
# Увеличиваем номер скролла
scroll_number += 1
# Собираем ссылки из текущего состояния блока
print("Начинаю собирать ссылки")
org_links = [a.get_attribute("href") for a in driver.find_elements(By.CLASS_NAME, "search-snippet-view__link-overlay")]
print("Ссылки собраны")
# Закрытие браузера
driver.quit()
# Сохраняем ссылки в файл
with open("org_links.txt", "w") as file:
for link in org_links:
file.write(link + "\n")
print("Ссылки сохранены в файл org_links.txt")
Сбор информации об организации со страницы
import time
import csv
from selenium import webdriver
from selenium.webdriver.common.by import By
# Открываем файл с ссылками на страницы организаций
with open("org_links.txt", "r") as f:
org_links = f.read().splitlines()
# Инициализация браузера
driver = webdriver.Chrome()
# Создаем CSV-файл для записи
csv_filename = "org_info.csv"
csv_file = open(csv_filename, "w", newline="", encoding="utf-8-sig")
csv_writer = csv.writer(csv_file, delimiter=";") # Используем разделитель ;
csv_writer.writerow(["Название", "Адрес", "Сайт", "Телефон", "Вконтакте", "WhatsApp", "Telegram"]) # Добавляем заголовки столбцов
# Проходимся по каждой ссылке и записываем информацию в CSV
for link in org_links:
driver.get(link)
# Проверяем наличие элемента с указанным классом
h1_element = driver.find_elements(By.CLASS_NAME, "orgpage-header-view__header")
if h1_element:
h1_text = h1_element[0].text.strip()
# Получаем информацию об адресе
address_element = driver.find_elements(By.CLASS_NAME, "orgpage-header-view__address")
if address_element:
address_text = address_element[0].find_element(By.TAG_NAME, "span").text.strip()
else:
address_text = "Адрес не найден"
# Получаем информацию о сайте
site_element = driver.find_elements(By.CLASS_NAME, "business-urls-view__link")
if site_element:
site_href = site_element[0].get_attribute("href")
else:
site_href = "Сайт не найден"
# Получаем информацию о телефоне
phone_element = driver.find_elements(By.XPATH, "//span[@itemprop='telephone']")
if phone_element:
phone_text = phone_element[0].text.strip()
else:
phone_text = "Телефон не найден"
# Получаем информацию о Вконтакте
vk_element = driver.find_elements(By.XPATH, "//a[@aria-label='Соцсети, vkontakte']")
if vk_element:
vk_href = vk_element[0].get_attribute("href")
else:
vk_href = "Ссылка на Вконтакте не найдена"
# Получаем информацию о WhatsApp
whatsapp_element = driver.find_elements(By.XPATH, "//a[@aria-label='Соцсети, whatsapp']")
if whatsapp_element:
whatsapp_href = whatsapp_element[0].get_attribute("href")
else:
whatsapp_href = "Ссылка на WhatsApp не найдена"
# Получаем информацию о Telegram
tg_element = driver.find_elements(By.XPATH, "//a[@aria-label='Соцсети, telegram']")
if tg_element:
tg_href = tg_element[0].get_attribute("href")
else:
tg_href = "Ссылка на Telegram не найдена"
csv_writer.writerow([h1_text, address_text, site_href, phone_text, vk_href, whatsapp_href, tg_href])
time.sleep(2) # Пауза на 2 секунды, если элемент найден
else:
print(f"Заголовок не найден на странице: {link}")
time.sleep(40) # Пауза на 40 секунд, если элемент не найден
# Закрываем браузер и CSV-файл
driver.quit()
csv_file.close()
print(f"Информация успешно сохранена в {csv_filename}")
Поиск email на сайте
import requests
from bs4 import BeautifulSoup
import re
# URL сайта
url = "https://babos.clients.site/"
print('Запустили поиск Email для сайта' + url)
# Отправляем GET-запрос на сайт
response = requests.get(url)
# Проверяем успешность запроса
if response.status_code == 200:
# Инициализируем BeautifulSoup для анализа HTML-кода
soup = BeautifulSoup(response.text, 'html.parser')
# Функция для поиска email адресов в тексте
def find_emails_in_text(text):
matches = email_pattern.findall(text)
return matches
# Функция для поиска email адресов на странице
def find_emails_in_page(page_soup):
email_addresses = []
for text in page_soup.find_all(string=True):
# Пропускаем JSON-LD данные
if "script" in text.parent.name and "application/ld+json" in text.parent.get("type", ""):
continue
matches = find_emails_in_text(text)
email_addresses.extend(matches)
return email_addresses
# Паттерн для поиска email адресов
email_pattern = re.compile(r'\b[A-Za-z0-9._%+-]+@(?:[A-Za-z0-9-]+\.)+[A-Z|a-z]{2,7}\b')
# Множество для хранения найденных email адресов (удаляет дубликаты автоматически)
email_addresses = set()
# Список для хранения найденных email адресов
# email_addresses = []
# Находим все ссылки с префиксом "mailto:"
mailto_links = soup.find_all("a", href=re.compile(r'^mailto:'))
# Извлекаем email адреса из ссылок с префиксом "mailto:"
for link in mailto_links:
email = link["href"][7:] # Убираем "mailto:" из начала ссылки
email_addresses.add(email)
# Ищем email адреса на главной странице
email_addresses.update(find_emails_in_page(soup))
if not email_addresses:
print('Email на главной странице не найден ищем страницу Контакты')
# Ищем ссылку на страницу контактов
contact_link = None
for link in soup.find_all("a"):
if "Контакты" in link.text:
contact_link = link.get("href")
break
if contact_link:
contact_url = url + contact_link
print('Ссылка на страницу Контакты' + contact_url)
# Отправляем GET-запрос на страницу контактов
contact_response = requests.get(contact_url)
# Проверяем успешность запроса на страницу контактов
if contact_response.status_code == 200:
contact_soup = BeautifulSoup(contact_response.text, 'html.parser')
# Список для хранения найденных email адресов на странице контактов
email_addresses = []
# Проходим по текстовым участкам на странице контактов и ищем email адреса
email_addresses.extend(find_emails_in_page(contact_soup))
# Удаляем дубликаты email адресов
unique_email_addresses = list(set(email_addresses))
# Выводим найденные email адреса
if unique_email_addresses:
for email in unique_email_addresses:
print(email)
else:
print("Email адреса не найдены на странице контактов.")
else:
print("Не удалось получить доступ к странице контактов")
else:
print("Ссылка на страницу контактов не найдена.")
else:
print('Нашли Email')
for email in email_addresses:
print(email)
else:
print("Не удалось получить доступ к странице")